Raspberry Turk
The Raspberry Turk is a robot that can play chess—it's entirely open source, based on Raspberry Pi, and inspired by the 18th century chess playing machine, the Mechanical Turk.

The vision aspect of the Raspberry Turk is based on a large dataset which consists of overhead images and the associated board state for each image. This dataset is publicly available on Kaggle, released under the (CC BY-SA 4.0) license.

Collection occured over several hours as I sat moving pieces very slightly. I took roughly 4 images of each piece in each square, in a different position/rotation in the square, and under different lighting conditions. Each frame captured includes:
| Type | Number per Frame |
|---|---|
| Empty | 30 |
| White Pawn | 8 |
| White Knight | 2 |
| White Bishop | 2 |
| White Rook | 2 |
| White Queen | 2 |
| White King | 1 |
| Black Pawn | 8 |
| Black Knight | 2 |
| Black Bishop | 2 |
| Black Rook | 2 |
| Black Queen | 2 |
| Black King | 1 |
The collection.py script provides a simple GUI for capturing chessboard frames and associated board FENs.
$ python -m raspberryturk.embedded.data.collection --help
usage: raspberryturk/embedded/data/collection.py [-h] [-s SEED] base_path
Utility used to capture chessboard images and associated FENs. While the
script is running use 'r' to rotate the pieces on the board, 'c' to capture
the current frame, and 'q' to quit.
positional arguments:
base_path Base path for data collection.
optional arguments:
-h, --help show this help message and exit
-s SEED, --seed SEED Random seed to initialize board.
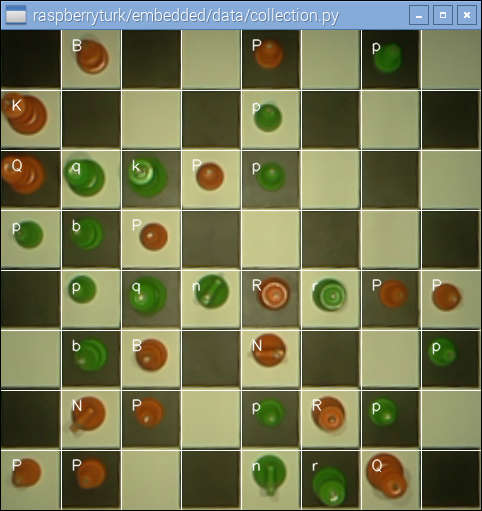
collection.py window.The collection.py script produces a series of folders which each contain 480x480px images and a board.fen file.
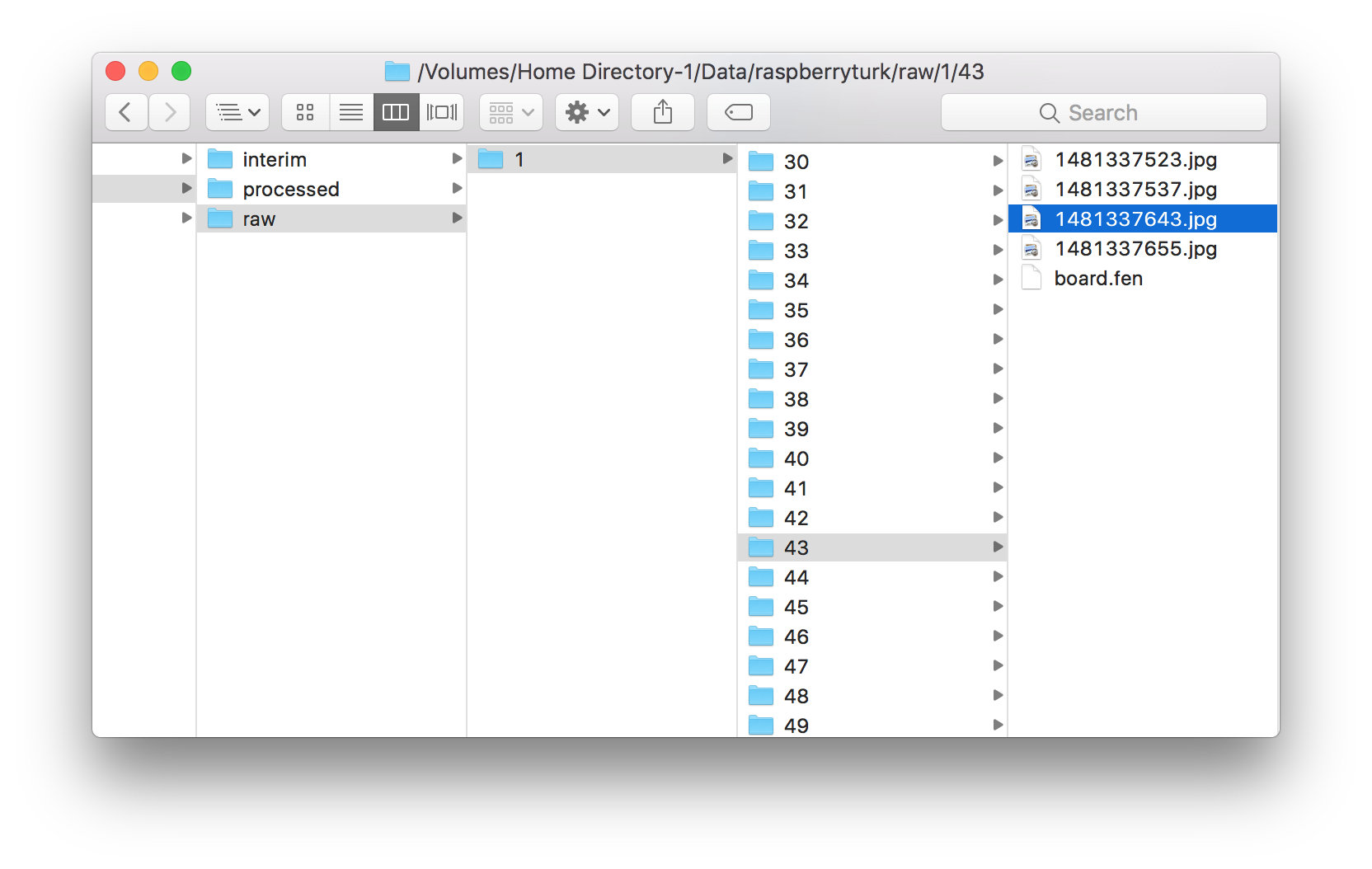

1481337643.jpgboard.fen:p1pqnRrP/2bB1N2/2NP1pRp/1PP2nrQ/2B2P1p/1K3p2/1QqkPp2/PpbP4
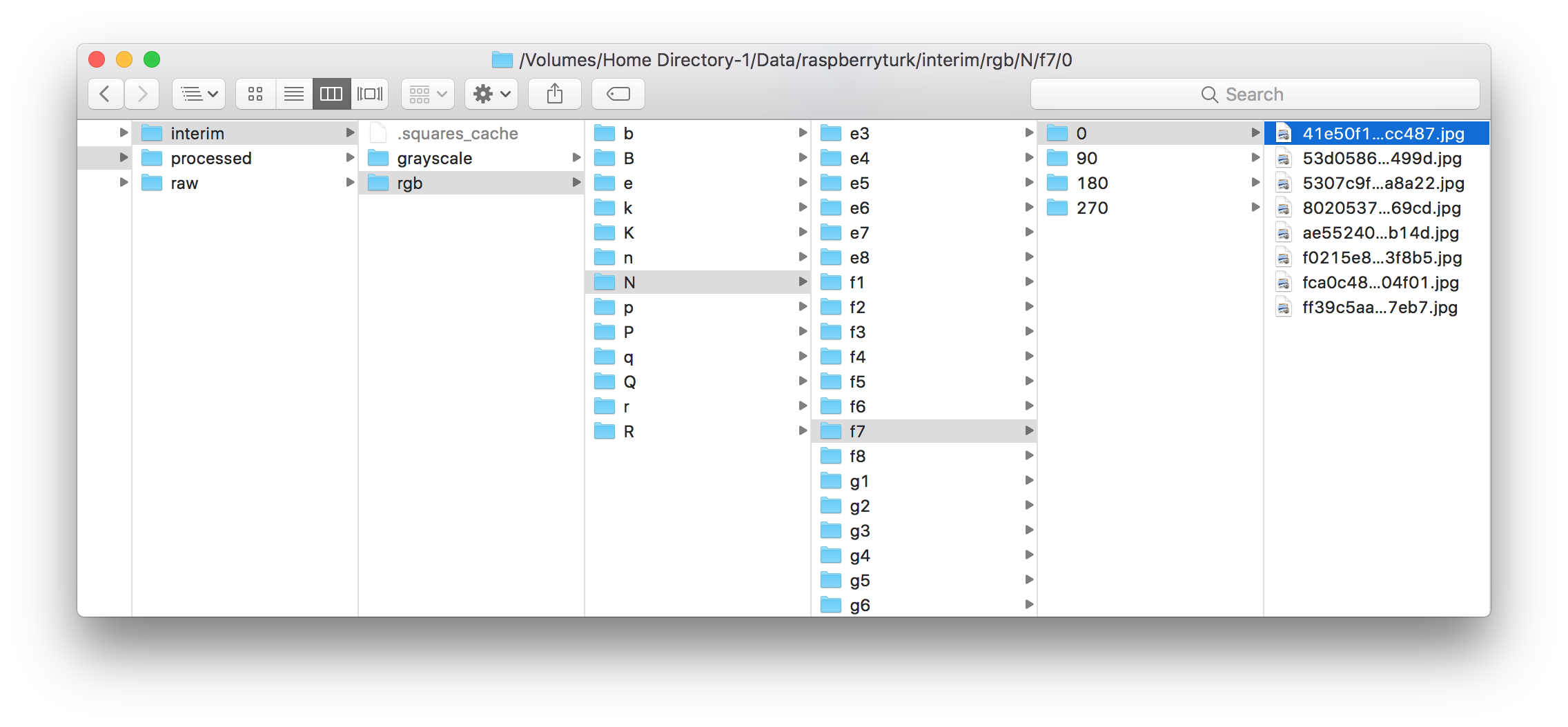
The process_raw.py script will take the full set of images and board FENs collected with collection.py and slice them up into labeled folders of individual 60x60px images. The script keeps track of which board images have been processed, so the next time the script is run it will only process newly captured images.
$ python -m raspberryturk.core.data.process_raw --help
usage: raspberryturk/core/data/process_raw.py [-h] [-x]
source_path target_path
Utility used to process raw chessboard image data collected by collection.py.
It goes through the contents of SOURCE_PATH, processes the collected data, and
stores the interim format in TARGET_PATH. By default it will keep track of
what raw data has been processed so it can be run multiple times without
reprocessing the same data.
positional arguments:
source_path Source path for data processing.
target_path Target path for data processing.
optional arguments:
-h, --help show this help message and exit
-x, --ignore_cache If True, this will delete all contents in the
target_path and reprocess everything.


The final step is to produce a complete encapsulated dataset that can be imported using np.load. Each dataset contains X_train, X_val, y_train, y_val, and zca (if the dataset is ZCA whitened) and can be customized in a number of ways as described below. Datasets are created using the create_dataset.py utility.
$ python -m raspberryturk.core.data.create_dataset --help
usage: raspberryturk/core/data/create_dataset.py [-h] [-g] [-r] [-s SAMPLE]
[-o] [-t TEST_SIZE] [-e] [-z]
base_path
{empty_or_not,white_or_black,color_piece,color_piece_noempty,piece,piece_noempty}
filename
Utility used to create a dataset from processed images.
positional arguments:
base_path Base path for data processing.
{empty_or_not,white_or_black,color_piece,color_piece_noempty,piece,piece_noempty}
Encoding function to use for piece classification. See
class_encoding.py for possible values.
filename Output filename for dataset. Should be .npz
optional arguments:
-h, --help show this help message and exit
-g, --grayscale Dataset should use grayscale images.
-r, --rotation Dataset should use rotated images.
-s SAMPLE, --sample SAMPLE
Dataset should be created by only a sample of images.
Must be value between 0 and 1.
-o, --one_hot Dataset should use one hot encoding for labels.
-t TEST_SIZE, --test_size TEST_SIZE
Test set partition size. Must be value between 0 and
1.
-e, --equalize_classes
Equalize class distributions.
-z, --zca ZCA whiten dataset.
Datasets can be created for different purposes. For example, in the chess_piece_presence.ipynb notebook, the dataset included color images with white/black/empty as the label. In the chess_piece_classification.ipynb notebook, the images are grayscale, the features are preprocessed using ZCA whitening, and the labels are queen/rook/bishop/knight.
Example usage:
$ python -m raspberryturk.core.data.create_dataset ~/Data/raspberryturk/interim/ promotable_piece ~/Data/raspberryturk/processed/example_dataset.npz --rotation --grayscale --one_hot --sample=0.3 --zca
Jupyter console 5.0.0
Python 2.7.13 |Continuum Analytics, Inc.| (default, Dec 20 2016, 23:09:15)
Type "copyright", "credits" or "license" for more information.
IPython 5.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: from raspberryturk.core.data.dataset import Dataset
In [2]: d = Dataset.load_file('/home/joeymeyer/Data/raspberryturk/processed/example_dataset.npz')
In [3]: print(d.metadata)
{
"base_path": "/home/joeymeyer/Data/raspberryturk/interim",
"encoding_function": "promotable_piece",
"equalize_classes": false,
"filename": "/home/joeymeyer/Data/raspberryturk/processed/example_dataset.npz",
"grayscale": true,
"one_hot": true,
"rotation": true,
"sample": 0.3,
"test_size": 0.2,
"zca": true
}
In [4]: import numpy as np
In [5]: np.set_printoptions(precision=4)
In [6]: print(d.X_train.shape)
(4812, 3600)
In [7]: print(d.X_train)
[[-0.6132 -0.374 -0.4225 ..., 0.2388 0.5081 1.2592]
[-2.3457 0.9484 1.4573 ..., 0.3943 0.8132 1.506 ]
[-1.8006 -0.4805 -0.3776 ..., -0.1239 0.071 0.7684]
...,
[-2.2504 0.5313 1.2553 ..., -0.0724 0.2431 0.9375]
[-1.8922 -0.6476 -0.6249 ..., 0.349 0.5621 0.3087]
[-1.6208 0.4695 0.1789 ..., 0.8657 0.931 0.9377]]
In [8]: print(d.y_train.shape)
(4812, 4)
In [9]: print(d.y_train)
[[1 0 0 0]
[1 0 0 0]
[1 0 0 0]
...,
[0 1 0 0]
[0 0 0 1]
[0 0 1 0]]
In [10]: print(d.X_val.shape)
(1203, 3600)
In [11]: print(d.y_val.shape)
(1203, 4)
In [12]: print(d.zca.shape)
(3600, 3600)